Basemap checker es un mini desarrollo que hice con el objetivo principal de practicar Javascript y de paso cañaso, armar una herramienta que sirva al momento de ir actualizando los estilos de los diferentes mapas base que desarrollamos en el Instituto Geográfico Nacional.
El desarrollo es un mapa en Leaflet utilizando el plugin side by side. El funcionamiento de éste se basa en tener dos layer o arrays de layers y dividir la pantalla en dos para visualizar uno u otro. Muy simple todo.
El plugin ya lo veniamos usando, pero los mapas base los cambiabamos directamente desde el archivo js. hardcodeando.
La mejora que le hicimos fue:
Agregar botones con los mapas base del IGN ( los que están en producción)
Agregar un menú desplegable para poder usar mapas base de otras empresas o instituciones (OSM, Google, Stamen, etc)
Agregar un input para poder usar otros mapas base. Ésto puede ser útil tanto para poner mapas que ignoramos cómo también para agregar los mapas de producción.
Algunas mejoras que se quedaron en el tintero para hacer:
mejorar toda la usabilidad, el css, etc
agregar algo que te diga cual es el mapa utilizado
guardar las url customizadas
agregar bookmarks
Por último, el código está publicado acá: https://github.com/martinfernandoortiz/basemaps_checker/
Este post tiene cómo objetivo describir una parte del trabajo que venimos haciendo dentro del Instituto Geográfico Nacional en relación a los diferentes geoservicios que producimos y en particular a los mapas base.
Lo primero para mencionar es que la producción de cartografía es una tarea compleja que implica la articulación de muchos actores y poner el ojo en una cantidad inigualable de detalles. Si a esto le sumamos el soporte digital, la complejidad se multiplica por cada nivel de zoom que tiene éste. Y acá es que entra en juego lo más importante en esta experiencia: tener un equipo de profesionales que le hacen frente a las distintas dificultades que se van presentando. Sin este equipo, hoy en día no tendríamos la calidad que tenemos en los diferentes mapas bases del IGN y esto no implica que el trabajo éste terminado si no que planteamos procesos de mejoras continua.
Argenmap
Argenmap es el proyecto que engloba a los diferentes mapas base que desarrolla el Instituto Geográfico Nacional. Éstos se pueden utilizar tanto en el visor de mapas del IGN, cómo también como mapas base para software GIS o embeberlos en aplicaciones. Además, cada uno de éstos mapas son parte de la cartografía digital oficial de la Administración Publica Nacional.
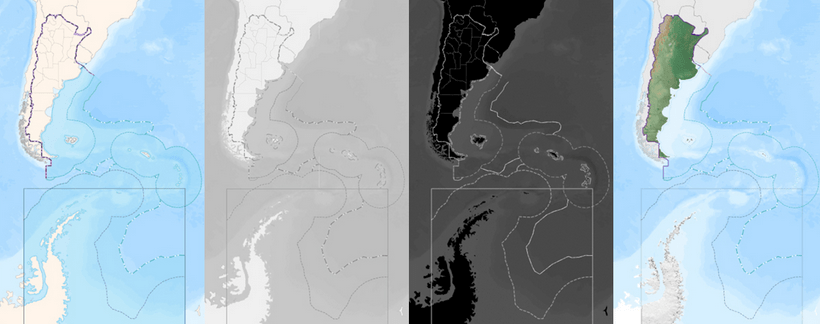
Actualmente llevamos desarrollados 5 mapas base: Argenmap, Argenmap Gris, Argenmap Oscuro, Argenmap Topográfico y Argenmap Híbrido. Los dos primeros ya se encontraban en producción al inicio de mi gestión cómo coordinador en el Departamento de Aplicaciones Geoespaciales. En éstos 3 años se le fueron haciendo mejoras en cuanto al etiquetado, simbología y a los estilos en general.
Cada uno de los mapas base que desarrollamos está pensado para diferentes tipos de usos y usuarios. Siendo el «argenmap común» un mapa base generalista, de todos los mapas base éste es el que contiene mayor cantidad de capas y etiquetas. Hasta éste momento (01/02/2024) está pensando para ser utilizados en contextos en donde no se necesita agregar muchas más capas.
Tanto Argenmap Gris cómo el Oscuro fueron desarrollados pensando en proyectos que necesitan agregar capas sin que ésto implique un «empaste» en la pantalla. Ambos son monocromáticos lo cual facilita el contraste de información. Nobleza obliga, antes de entrar al Instituto uno de los mapas base que más utilizaba en mis proyectos era el Carto Dark, desarrollado por la empresa española Carto. Nuestro mapa oscuro replica mucho algunos de los lineamientos que dicho mapa tiene.
El Argenmap Topográfico nació con el objetivo de combinar tanto topografía cómo también cobertura de suelo. La base de éste se basa en modelos digital de elevación, hillshades y una paleta de colores basada en la cobertura. Inicialmente se desarrollo solo para el Territorio Nacional (excluyendo el Sector Antártico Argentino) pero en la segunda versión se pudo trabajar la topografía de dicho sector cómo también la del resto de América Latina
El último desarrollo hecho es el Argenmap Híbrido. Éste mapa base está pensado para ser utilizado arriba de imágenes satelitales. Es el que menos capas y etiquetas contiene, teniendo solamente información básica de límites y red vial.
Desafíos y Dificultades
Actualmente el stack que se utiliza para éstos desarrollos es postgreSQL (con PostGIS) y Geoserver. Cada una de las capas, se sirven en Geoserver y los estilos están creados a través de archivos SLD. El código de ésto se encuentra publicado en el repositorio oficial del IGN.
Puede parecer redundante, pero los principales desafíos en este tipo de trabajos no tienen que ver con el diseño cartográfico y el desarrollo de código sino más bien con la definición de territorio y la discusión teórica acerca de que mensaje queremos transmitir con la cartografía digital. Esto conlleva, un proceso de documentación de las diferentes discusiones en torno al porque representamos lo que representamos.
Una de las dificultades que se presentan al momento de trabajar los estilos del mapa tiene que ver con la estructura de las tablas alojadas en la base de datos que siguen lineamientos relacionados a la tradición cartográfica del Instituto. Esto implica, que muchas capas están pensadas para la producción cartográfica impresa, y las necesidades al momento de generar geoservicios y cartografía digital puede diferir. El impacto de éste es que muchos estilos SLD terminan siendo códigos de proporciones bíblicas dada la cantidad de filtros que se le aplican
Otra de las tareas de gran dificultad es el etiquetado toponímico. La generación de etiquetas para diferentes niveles de zoom en un territorio tan extenso implica la creación de múltiples reglas y filtros para considerar todas las excepciones para tener un etiquetado consistente.
Por otro lado, es importante poder reproducir los mapas base en otras tecnologías analizando que potencialidades puede tener la utilización de éstas. Ésto puede impactar en el desarrollo de mapas en 3D o en las mejoras en las texturas y efectos de iluminación en las teselas.
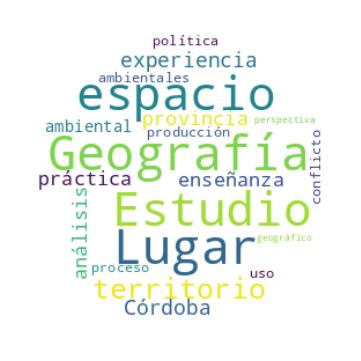
Algunas pruebas realizadas para hacer una nube de texto. Para éstos ejemplos utilicé la última circular del Congreso Nacional de Geografía de Universidades Públicas. El principal objetivo de ésto fue practicar un poco de DataViz con Python tratando de ver cuales eran las palabras más frecuentes en los títulos de las ponencias .
Cómo todo trabajo con Datos, la parte más dura es la de limpieza. En este caso, se intentó quitar de la circular la mayor cantidad de texto que meta ruido. Luego de ésto, se realizó un listado de stopwords que se fue depurando a medida que se realizaban las imágenes.
El repositorio se encuentra acá para utilizar tanto el texto cómo el notebook.
Algunas de las imágenes generadas:
wordcloud = WordCloud(width=800, height=400, relative_scaling=0.5,
background_color="black",
max_font_size = 42, min_font_size = 6,
colormap = "tab20c",
#max_words = 3,
#contour_width = .1, contour_color = "grey",
stopwords = stopwords_total).generate(text)
# Muestra la WordCloud con matplotlib
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title("Nube Dark", fontsize=16, color="#ff7f0e")
# Guarda la figura antes de mostrarla
plt.savefig('/content/drive/MyDrive/datasets_colab/imagenes/wordDark.jpg', bbox_inches='tight', dpi=75)
# Muestra la figura después de guardarla
plt.show()
mask = np.array(Image.open("/content/drive/MyDrive/datasets_colab/argentina.jpg"))
wc = WordCloud(height=300, width=300, background_color="black", repeat=True,
mask=mask,
max_font_size=42, min_font_size=6,
colormap="tab20c",
stopwords=stopwords_total)
wc.generate(text)
plt.figure(figsize=(20, 10))
plt.axis("off")
plt.imshow(wc, interpolation="bilinear")
plt.title("Nube Argentina Dark", fontsize=16, color="#ff7f0e")
# Guarda la figura antes de mostrarla
plt.savefig('/content/drive/MyDrive/datasets_colab/imagenes/wordArgDark1.jpg', bbox_inches='tight', dpi=75)
# Muestra la figura después de guardarla
plt.show()
#Forma Imagen
mask = np.array(Image.open("/content/drive/MyDrive/datasets_colab/argentina.jpg"))
wc = WordCloud(height = 300, width = 300, background_color="white", repeat=True,
mask=mask,
max_font_size = 42, min_font_size = 6,
#colormap = "magma",
#max_words = 3,
#contour_width = .1, contour_color = "grey",
stopwords = stopwords_total)
wc.generate(text)
plt.figure(figsize=(20, 10))
plt.axis("off")
plt.imshow(wc, interpolation="bilinear")
plt.title("Nube Argentina", fontsize=16, color="#440154")
# Guarda la figura antes de mostrarla
plt.savefig('/content/drive/MyDrive/datasets_colab/imagenes/argentina.jpg', bbox_inches='tight', dpi=75)
# Muestra la figura después de guardarla
plt.show()
#Forma de Circulo
x, y = np.ogrid[:300, :300]
mask = (x - 150) ** 2 + (y - 150) ** 2 > 130 ** 2
mask = 255 * mask.astype(int)
wc = WordCloud(height = 300, width = 300, background_color="white", repeat=True,
mask=mask,
max_font_size = 42, min_font_size = 6,
#colormap = "magma",
max_words = 20,
#contour_width = .1, contour_color = "grey",
stopwords = stopwords_total)
wc.generate(text)
plt.figure(figsize=(6, 6))
plt.axis("off")
plt.imshow(wc, interpolation="bilinear")
plt.title("Nube con stopwords - 20 palabras", fontsize=12, color="#440154")
# Guarda la figura antes de mostrarla
plt.savefig('/content/drive/MyDrive/datasets_colab/imagenes/circulo20.jpg', bbox_inches='tight', dpi=75)
# Muestra la figura después de guardarla
plt.show()
Al instalar un sistema GNU-Linux desde un pendrive notamos que luego de tener la instalación terminada; cuando queremos volver a utilizar nuestro USB para almacenamiento de archivos notamos que éste no tiene espacio. En general lo que va a suceder es que el pendrive va a detectar dos particiones: una con los archivos del sistema y otra partición con muy poco espacio.
Lo que sucede con esto, es que al momento de quemar la imagen y hacerla booteable le cambiamos el formato al pendrive. Los pasos a seguir para restaurarlo desde GNU Linux son muy sencillos:
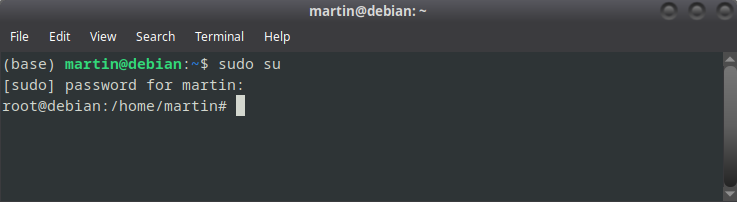
Desde la terminal, vamos a acceder con permisos root:
sudo su
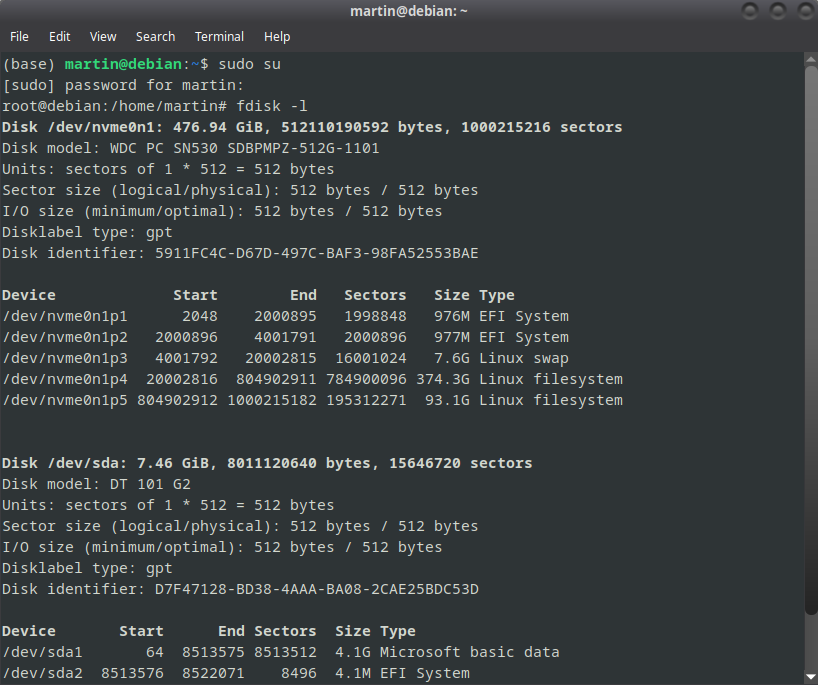
Vamos a listar las diferentes particiones que tiene la PC (tanto en los discos ŕigidos cómo también en los dispositivos enchufados). En este ejemplo, vemos que el dispositivo con almacenamiento de 7.46 gb es el pendrive que está en /dev/sda
fdisk -l
OJO! Si no estás seguro de cual es podes desconectar el pendrive y volver a poner el comando fdisk -l . De ésta forma chequeas si efectivamente las particiones que aparecian eran las del pendrive o no.
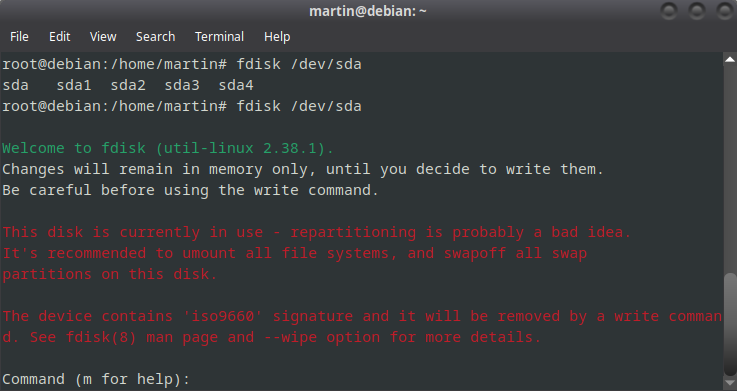
Vamos a seleccionar la partición que reformatearemos. En nuestro caso es la partición /dev/sda
fdisk /dev/sda
Luego de escribir esto, sale una advertencia bastante intimidante:
Achtung!!!!, la podes cagar! tene cuidado lo que tocas acá!
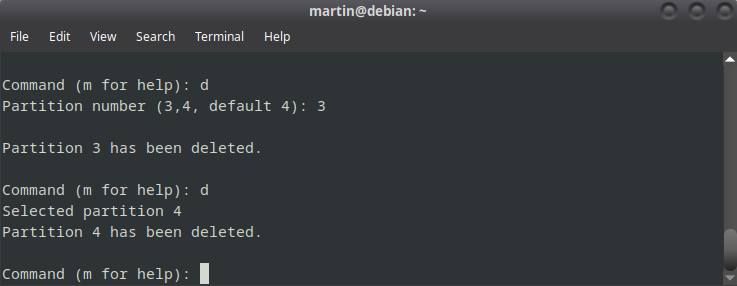
Luego de esto vamos a eliminar partición por partición del pendrive. En este caso eran 4 pero probablemente en tu pendrive sean 2. Usamos el comando d, tocamos enter y luego el número de la partición
d
1
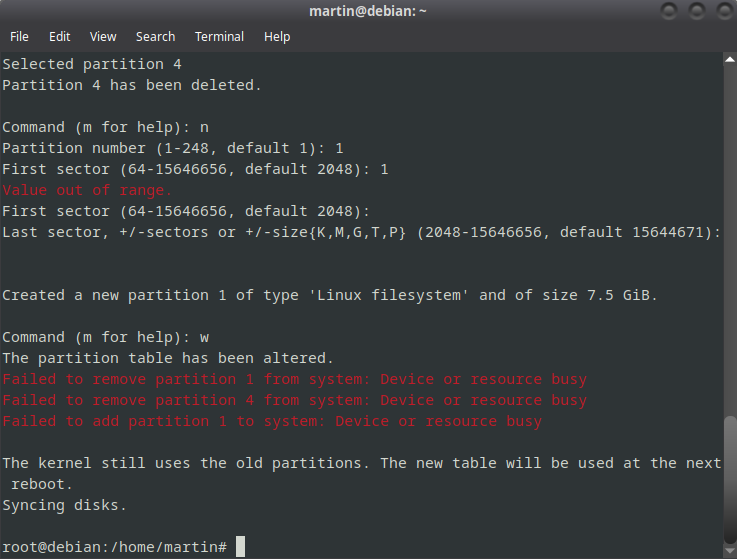
Vamos a crear una nueva partición. Va a ser la partición 1 y le vamos a asignar un espacio de inicio y otro de fin. Si nuestro pendrive solo va a tener una partición, cuando pregunte «First Sector» tocamos enter y luego cuando pregunte «Last Sector» hacemos lo mismo. Con el comando w escribimos los cambios
p
1
w
Desmontamos la partición y a partir de ésto le damos el formato. Primero escribimos
umount /dev/sda1
mkfs.vfat -F 32 -n USB /dev/sda1 -I
Esto fue todo amigues!
Sintetizando (cada línea es un enter). Tene cuidado de ver si el pendrive en cuestión es sda o sdb, sdc, etc….
sudo su
fdisk -l
fdisk /dev/sda
d
1
d
2
d
3
d
4
p
1
w
umount /dev/sda1
mkfs.vfat -F 32 -n USB /dev/sda1 -I
En el mes de junio 2023 se celebraron las jornadas de IDERA en Santa Rosa – La Pampa – Argentina. Para esta ocasión, junto al equipo de la Dirección de Información Geoespacial del Instituto Geográfico Nacional preparamos un taller de estilos aplicados a Geoserver.
A continuación quiero compartir la documentación que fuimos generando para la instalación de Geoserver. Si quieren ver el repositorio, éste es el link
¿Qué es Geoserver?
Geoserver es un servidor web de código abierto desarrollado en Java, multiplataforma, que permite a los usuarios compartir y editar datos geoespaciales. Diseñado para la interoperabilidad y publicación de datos de cualquier fuente de datos espaciales con estándares abiertos.
¿Es el único Servidor de datos geográficos open source?
No, no es el único. Existen otras alternativas cómo mapserver
Guía de instalación
Hay múltiples formas de instalar geoserver: con los instaladores, a través de docker, a través de una máquina virtual, usando OSGeo Live, etc. Los pasos acá sugeridos están pensados para hacer pruebas y no para un entorno de producción. Para esto último, no dudes en consultar a tu informático amigo 😉 . Por otro lado, también es importante señalar que el mejor camino es vía docker (estes en el Sistema Operativo que estes). Puede parecer un poco intimidante usar docker para aquellos que no venimos de las Ciencias de la Computación pero la instalación es más rápida y evita problemas de dependencia y errores.
Algunas ventajas de usar docker:
con docker ya instalado en tu PC, cuando pruebes geoserver va a andar o andar
no vas a tener que instalar nada extra para que funcione. En el caso del instalador de Windows necesitas hacer varios pasos extras y todo depende de cada compu
tanto la instalación cómo la desistalación no te va a generar ningún inconveniente de dependencias
vas a poder usar docker para probar otras herramientas. En el caso del software dedicado a la generación y procesamiento de información geoespacial es muy útil. Ejemplos: si vas a usar R o Python…
Instalación de Geoserver en Windows
Antes de instalar geoserver vas a necesitar tener instalado Java 64 bits JRE o JDK. Podes descargarlo desde acá
Si ya tenemos docker instalado, en una terminal ( pone en inicio «cmd» y abrila) escribir:
docker pull docker.osgeo.org/geoserver:2.24.x
Lo que hace este comando es descargar la imagen oficial de geoserver para Docker
Para correr el contenedor:
docker run -it -p8080:8080 docker.osgeo.org/geoserver:2.24.x
Si queremos utilizar el contenedor con una carpeta para poner data (shapes, etc) debemos correr
docker run -v C:\Users\martin\Documents\docker:/opt/geoserver_data -it -p8080:8080 docker.osgeo.org/geoserver:2.24.x
en donde C:\Users\martin\Documents\docker es la carpeta donde irán los shapes o capas a subir
Instalación en GNU-Linux vía docker
Si usas alguna distribución GNU-Linux te sugerimos que optes por la instalación vía docker; de esta forma no vas a tener problemas de dependencias ni nada de eso. Solo necesitas tener instalado docker, docker compose y permisos de administrador.
En la imagen se ve que se agregó sudo para tener los permisos de administrador
Para correr el contenedor:
docker run -it -p8080:8080 docker.osgeo.org/geoserver:2.24.x
Si queremos utilizar el contenedor con una carpeta para poner data (shapes, etc) debemos correr
docker run --mount type=bind,src=/home/martin/Documents/docker,target=/opt/geoserver_data -it -p8080:8080 docker.osgeo.org/geoserver:2.24.x
o sino
docker run -v /home/martin/Documents/docker:/opt/geoserver_data -it -p8080:8080 docker.osgeo.org/geoserver:2.24.x
en donde /home/martin/Documents/docker es la carpeta donde irán los shapes
Geoserver vía OSGeo Live
OSGeoLive es un DVD de arranque autónomo, unidad USB o máquina Virtual basada en Lubuntu, que permite probar una gran variedad de software geoespacial de código abierto sin necesidad de instalar algo particular. Se compone enteramente de software libre, lo que le permite ser libremente distribuido, duplicado y compartido. Para conocer más acerca de éste proyecto ingresa aquí: https://live.osgeo.org/es/
Dentro de todos los programas que componen a OSGeoLive se encuentra Geoserver. Podemos utilizar esta distribución tanto desde una maquina virtual como tambien desde un usb de arranque. Para cualquiera de las dos opciones vamos a descargar el archivo desde https://live.osgeo.org/es/download.html.
Para este ejemplo, necesitamos instalar una máquina virtual descarga Oracle Virtual Box desde acá y descargar el archivo de OsGeoLive en formato vm ( consulta acá )
Desde un USB de arranque
Necesitas cualquier programa para generar un usb de arranca (booteable).
Etcher Balena es un programa multiplataforma (tanto para Windows cómo para GNU Linux )
Mucha agua pasó por el puente desde la primera vez que instalé Debian 11. Si bien la experiencia fue muy buena, cuando tenes las particiones de disco ordenadas, la tentación de ir probando nuevos distros y sabores es grande. Sumado a que tuve la suerte de comprarme una nueva notebook; eso abrió el debate de que distro usar para una Lenovo 2 en 1 (pantalla táctil y esas cosas) con Windows
Ubuntu + GNOME
La primera prueba que hice fue instalar un Ubuntu con GNOME. La elección tenía más que ver con que estaba corto de tiempo y entendía que podía ser la distro que le tenga que poner menos mano. La experiencia fue muy buena: anduvo todo de 10 desde el primer momento: pantalla táctil, rotación, lapiz, teclado en pantalla. El único elemento que no anduvo fue el lector de huella lo cual según algunos foros de internet tiene que ver con la encriptación que tiene ese driver sumado a la cuestión de seguridad (que se yo…). El tema con GNOME es que no me resulta práctico así cómo viene. Si bien se puede configurar con GNOME Tweaks no me convence. Lo principal es el tema de cómo manejar las diferentes cosas que uno va abriendo en el sistema (navegadores, editores, GIS, fotos, etc). Suelo tener mil cosas funcionando al mismo tiempo y lo que necesito de la interfaz es algo bien conservador: abajo/arriba en donde pueda ir viendo todas las cosas que están abiertas (no depender de Alt + Tab) y algún cosa extra cómo el menú de inicio, la hora, etc. Que no se mal entienda. Me parece muy bueno el trabajo de diseño que lleva adelante GNOME pero en ésto tengo el chip «windows». De todos modos, no faltó oportunidad de probar configuraciones que fueron compartiendo otros usuarios, simular un estilo tipo MAC, etc.
Ubuntu Mate + Kubuntu
Después de ésto decidí instalar Mate en el mismo sistema ya que en general me gusta la estética simplona que tiene, la gestión de ventanas, etc. El punto fue que el GNOME Tweaks tenía mucha mano encima y había algunas cosas que me parecia que no estaban andando bien. A su vez, había un poco de quilombo en la Sources List, entonces decidí que era tiempo de empezar de 0. El sistema elegido fue Kubuntu (un Ubuntu + KDE que ya viene de fábrica). Éste sistema lo tuve varios meses. No le instalé GNOME porque la realidad es que la funcionalidades de tablet y rotación de pantalla automática no las uso (para la próxima compra de notebook evitar ésto que para el uso que le doy es al pedo)
¿Que pasó con Kubuntu? La verdad no recuerdo bien, Lo que más me gusta de Kubuntu son los chiches (widgets) que trae para poner en el escritorio. Por otro lado, hay una boludes que no me gusta del gestor de ventanas que es cómo buscar un archivo o escribir un path. En ese entonces, estaba haciendo pruebas de procesamientos pesados y estaba bastante pelado el sistema. Es decir, no estaba usando ningún tipo de widget. Sumado a esto, sale la nueva versión de Debian. Debian 12 Bookworm
Debian 12 Bookworm
Elegí instalar Debian 12 con Cinnamon. Nunca había usado este sabor porque lo veía muy parecido a Mate y en líneas generales poco atractivo. Sin embargo, le dimos una oportunidad. La instalación de Debian no tuvo ninguna dificultad. El instalador es un instalador normal sin ninguna historia (creo que es calamares pero no estoy seguro – esto paso hace unos meses).
En cuanto a la estética y lo que ofrece Cinammon todo simple pero muy funcional
Algunos detalles que me gustaron de está versión:
atajos en la consola: no es que las otras Distros no lo tengan pero si me ha pasado en algún Debian que tenía que configurar aparte para que se genere el autocompletado con TAB
atajos de teclado: lo mismo que antes. Los atajos que más uso ya vienen configurados. En Kubuntu ésto lo tuve que hacer aparte
atajos en los bordes de pantalla: es un chiche pero para cambiar de espacio de trabajo o minimizar todo me sirve
panel de inicio: tiene todo lo que necesito, organización temática, buscador con teclado
buscador al escribir cualquier letra en el gestor de ventanas
En cuanto al funcionamiento, nada malo para decir. Todo lo que esperaba de Debian, velocidad y estabilidad. Al menos en los programas que uso.
Una de las cosas que fui aprendiendo con el tiempo, además de tener ordenadas las particiones para poder empezar de cero sin perder información, es a sistematizar la instalación de los programas que uso. La realidad es que los programas que tengo que instalar no son muchos y son siempre los mismos: QGIS, R (R Studio y toda la bola), algún idle de Python, Grass, Saga, GDAL, Docker VS Codium, Chromium, Blender, Inkscape, y algún que otro programa. Si bien no tengo un archivo bash al 100% casi que ya está sistematizada la instalación de las cosas que voy usando, las dependencias, etc. Si quieren chusmear, pueden acceder desde acá . La idea es en algún momento ir documentando mejor y armar bien el bash para que éste 100% automatizado. Por lo pronto, así cómo está me sirve para no olvidarme de nada aunque lo vaya haciendo manualmente.
Por último, también tengo instalada una versión de GNOME en éste Debian 12. La verdad que no la uso nunca, pero la instalé porque quería probar cómo andaba con el tema del modo Tablet, Lapiz, Rotación etc. El funcionamiento es óptimo nada para decir. Solo que el 99% del tiempo uso Cinammon.
A modo de cierre, uno no sabe cuando va a cambiar de Distro y Sabor pero tanto Kubuntu cómo Debian 12 Cinammon están muy bien para probar y para darle uso todos los días.
La intención de está entrada es contar las primeras sensaciones usando Debian 11. En primer lugar, no soy administrador de sistemas ni un usuario avanzado de GNU Linux. Si bien desde el 2019 utilizo GNU Linux, en este tiempo no me dedique a estudiar el sistema en detalle. Solamente hacer instalaciones personales ( a través de Calamares), agregar o sacar repositorios e instalar y desinstalar programas con la terminal. Dado estos conocimientos básicos, Debian siempre había parecido un cuco. Tiene fama de ser dificil de usar y que es facil de “cagarla” sino estás muy en tema.
Mi historial GNU Linux
Cómo mencionaba, desde el 2019 elijo usar (cada vez que puedo) software libre. Si bien había tenido algunas experiencias anteriores, allá por el 2009 o 2010, instalando Ubuntu y Linux Mint en la búsqueda de una interfaz más similar a Windows, en ese entonces no sabía de la filosofía del Software Libre. Las experiencias habían sido buenas pero la necesidad de usar Arcmap me ancló a Windows.
En el 2019, me uní al Club del Software Libre y realicé un taller de instalación. El resultado fue tener un dual boot durante dos meses entre Windows 10 y Ubuntu Studio, y luego de eso me di cuenta que el Windows ya no lo usaba ni tampoco lo necesitaba.
Había elegido Ubuntu Studio porque me llamaba mucho la atención la cantidad de programas que venían enfocados a la producción audiovisual. Luego de unos meses cambie a Ubuntu Mate ya que los programas esos no los usaba y quería algo más limpio.
En estos años, Ubuntu (el 18 y el 21.04) anduvo muy bien. El sabor tenía todo lo que necesitaba, y los programas que uso (QGIS, R Studio, Anaconda, Inkscape, GIMP, Atom y Steam) también respondieron bien. Solo que estas últimas semanas empezó a fallar con algunos congelamientos que me forzaron a resetear y perder algunas cosas mínimas. Dado que estaba por tener vacaciones era el momento de probar una distro nueva, cosa que si tenía algún problema tenga el tiempo para arreglarlo o en el peor de los casos volver a una instalación limpia de Ubuntu.
Migrando a Debian
La principal fama de Debian es que es estable y eso es lo que estaba buscando después de tener esos congelamientos en la compu, un sistema estable que no se cuelgue. La segunda fama que tiene es que no es la más amigable para usuarios novatos. Con el primer punto – hasta ahora coincido – con el segundo no del todo.
Considero que es super importante probar la distribución antes de instalarla (a menos que tengamos una máquina de pruebas). En mi caso, armé una máquina virtual, por un lado, viendo el live, y por otro, para probar el instalador, a ver si tenía algo complicado o algo que tuviera que investigar.
Otro elemento relevante, es realizar la migración con tiempo. Cuando hablo de la migración, hablo desde el momento en que investigamos que distro queremos, probarla, instalarla e instalar los programas que usamos. Es decir, un tiempo pre instalación, y también un tiempo post instalación para dejar todo “pipicucu”.
A su vez, y no menos importante, pensar bien las particiones. Lo más facil es hacer la instalación automática, que el instalador se encargue de las particiones. El tema es que a largo plazo esto implica mayor tiempo de backup y más vueltas si queremos instalar varias distros, o si queremos volver a instalar una distro de cero. En mi caso, tengo una partición para el boot, otra swap, otra root y otra para el home (donde pongo mis archivos, documentos, descargas, bla). Esto me permitió que al tener el home en una partición aparte, todos mis archivos sigan estando con el mismo orden y en el mismo lugar, con la migración de Ubuntu a Debian.
El instalador que use se llama “Calamares” y basicamente es un instalador gráfico que te va diciendo que hacer (elegir donde estás, idioma, teclado, si queres particionar y la instalación). No recuerdo cuanto tiempo me llevo instalar pero habrá sido entre 15 y 30 minutos. La iso la descargue de este link que es la versión con controladores privativos. Y el sabor que elegi es KDE. Entiendo que puede haber otros instaladores en donde el usuario tiene mayor control de lo que instala, en mi caso no quise probar algo nuevo y la verdad que no hubo problema. Se instaló todo, resetie y CHAN… Error de Grub!
En ese momento putie un poco pero fue una falsa alarma. No se bien que hice, si desactive el secure boot, o pase a modo UEFI o que (esas son cosas que no entiendo mucho) pero al cambiar eso booteo perfecto y ya estaba usando Debian.
Los chiches de KDE
Una de las razones por las que elegí el sabor KDE sobre Mate (que venía usando antes) es que KDE tiene miles de opciones, widgets y cosas que hacen que la compu se vea re contra cheta. Creo que lo primero que hice con el sistema fue probar estas cosas y si bien hay templates de usuarios y se puede agregar botoncitos y “cositas” lo más funcional para mi sigue siendo lo más sobrio en cuanto a diseño.
A la derecha de la pantalla, agregue unos widgets de rendimiento (memoria, cores, cpu use), una barra inferior con algunos íconos favoritos, que está abierto y el minimizador, y por último, arriba a la derecha otra barra con la hora y algunas opciones de dispositivos (wifi, bluetooth, conexión, display, avisos, sonido).
Instalación de aplicaciones
La instalación de aplicaciones, al menos las que uso yo, no difiere mucho de Ubuntu. Algunas están en el centro de software y otras se hacen a través de la sources.list. Por ejemplo, QGIS se puede instalar agregando repositorios o a través de Discover, el centro de software.
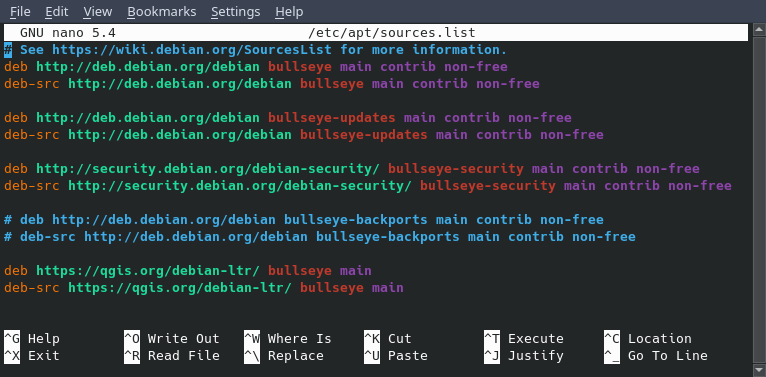
En cuanto a la sources.list simplemente tengo agregado repositorios non free y los repositorios de QGIS
Y los drivers?
La verdad es que la instalación que use me dejo todo andando: wifi, bluetooth, audio, mic, placa de video. Pero con esto último si hubo algunas idas y vueltas. Mi laptop tiene dos placas de video: una onboard y otra nVidia que uso para juegos. La instalación que hice yo instala drivers para la placa nVidia no privativos. Más allá de los drivers, privativos o no privativos, a la hora de correr juegos en Steam (el CSGO) lo primero que pasaba es que estos se ejecutaban usando la placa onboard, lo cual bajaban mucho los FPS.
Al instalar, los drivers privativos esto seguía sucediendo y ahi empecé a “meter mano”. Y si bien esta es una forma de aprender a veces podemos romper algunas cosas. En mi caso, el “meter mano” implico agregar repositorios de testing, backports, actualizar todo el sistema, y a partir de eso, actualicé kernel, drivers y demás. El resultado fue que los juegos empezaron a usar la placa de video nVidia pero después de unos minutos se tildaba todo al momento de jugar. Fuera de los juegos todo andaba impecable.
A partir de eso, decidí volver a atras instalando todo de 0. Cómo la instalación había sido fácil lo mejor era empezar con una instalación “fresca”. Si bien fueron varias horas con prueba, la placa funcionó. A diferencia de Ubuntu en donde había una opción de actualización en donde elegía que drivers quería, acá tuve que seguir algunos pasos que están muy bien documentados y a su vez, cuando quiero utilizar la placa tengo que ejecutar una serie de comandos para activarla. Algo asi como ejecutame esto usando tal placa. Seguramente esto se puede mejorar armando un acceso directo, por ahora esta solución me alcanza.
Todo el tema de los drivers nVidia fue lo que más dolor de cabeza me dio, creo que fue una buena experiencia para aprender un poco más del sistema. Por otro lado, quizás con los drivers no privativos probablemente también sirva esta solución, pero ahora prefiero no cambiar. Estoy con el kernel 5.10 y drivers nvidia 460…
Conclusiones prematuras
La experiencia usando Debian 11 viene siendo muy buena. Es cómo tener una compu nueva ( por rendimiento y por estética). La usabilidad del sistema para un usuario novato o seminovato cómo yo, hasta ahora es muy similar a Ubuntu. La instalación fue impecable y termino con todo operativo (uno de los miedos alrededor de GNU Linux). El tema de drivers nVidia puede ser algo hincha huevos pero puede pasar en todas las distribuciones pero a diferencia de Ubuntu (que es de donde vengo) creo que Debian tiene una documentación más robusta y no es poca cosa. En general, cualquier duda de Ubuntu la resolvía en stackexchange. En este caso, los primeros y mejores resultados fueron los que vienen de la wiki de Debian con paso a paso y explicaciones entendibles para usuarios no avanzados. Un ejemplo de esto, es que no solo muestran diferentes formas de instalar drivers privativos sino que hay una wiki especifica para usar Steam. En este sentido, y una de las cosas que más me sorprende del software libre vs el software privativo es la documentación y la ayuda de la comunidad. Para este último, hay un cierto “status quo” de la documentación y de las ayudas. En otras palabras, suele pasar que en los foros, las respuestas oficiales tienden “esto tiene que funcionar asi y punto!” (mirar foros de PowerBI o ESRI). Con el software libre, la documentación y las ayudas están más humanizadas entendiendo el ecosistema de usos y problemas que puede haber. Pero sin extenderme mucho en esto, me sorprendio y para bien la documentación en Debian.
Cómo conclusión final, la cantidad de distribuciones para probar es muy amplia y hay mucha variedad según que uso le demos a nuestras PC. En tanto y en cuanto, tengamos una máquina virtual para hacer pruebas y un poco de tiempo, mi recomendación es que investiguen y vean que es lo que buscan en su informática y seguramente encuentren una distribución GNU Linux que les cierre. Se van a dar cuenta que el software libre no solamente no muerde sino que es funcional y transparente.
Marzo 2020, empieza la pandemía, incertidumbre, confinamiento y Counter Strike…. Resulta que pocos días de dictarse el confinamiento en Argentina, se organizaron unas partidas de Counter Strike Global Offensive. Lo que empezó con un rato de distracción derivo en un nivel de manija importante. Jugamos casi todos los días a las 19hs durante 7 meses seguidos de dos a tres horas sumando miles de mensaje en el grupo de wasap discutiendo las partidas (Estudio Counter se llamó off the record).
El punto es que en algún momento se investigo sobre la posibilidad de obtener estadísticas de cada partida, se armaron tablas para completar manual pero nada de eso prospero.
library(CSGo)
Julio 2021, en una de tantas noches de insonmio veo que existe una API de CSGO para utilizar con R Studio (Gracias Adson Costanzi Filho). A partir de eso, la manija se apoderó de mi y decidí armar una shiny app… un poco para fogonear en el grupo, otro poco para practicar un poco de shiny y no oxidarme.
Por si no les interesa, el código, el link a la app está acá. Sino acá va un poco del esqueleto de la APP…
Tres cosas importantes:
necesitamos credenciales para usar la api . Si escribimos en r vignette("auth", package = "CSGo")nos aparece el paso a paso para conseguir la credencial de la api
necesitamos nuestro user id, o el user id de algún amigo. Para ésto debemos ir a nuestro perfil de steam y desde ahí vamos a ver que la url tiene un formato similar a este: ‘https://steamcommunity.com/profiles/76561198263364899/’ En este caso, el user id son todos esos números que aparecen en la URL
Por último tenemos que poner la configuración de nuestro perfil en “público” de lo contrario no vamos a obtener ningún dato cuando utilicemos la API. Para eso último debemos ir a Editar Perfil dentro de Steam y dejar configurado el perfil cómo aparece en la imagen
Luego de todo ésto arrancamos en R. La idea de la APP era tener una parte de gráficos comparativos (siempre jugamos los mismos y esto servía para picantear quienes eran los mejores rankeados o los peores) y otra parte con estadísticas individuales utilizando un filtro reactivo con los jugadores.
# Instalamos el paquete y lo cargamos
install.packages("CSGo")
library(tidyverse) #para no perder la costumbre
library(CSGo)
Con el código get_stats_friends
csgo_stats <- get_stats_friends(api_key = 'tuAPI, user_id = 'tuID') #el resultado es una lista
df <- as.data.frame(csgo_stats$friends_stats) #lo pasamos a df para trabajar más cómodo
view(df)
Vamos a ver que el data frame que creamos tiene un formato long. En name podemos ver algunos de los indicadores que arroja la API. Realmente es muy variada la info que da y puede llegar a marear. En mi caso, creo que me costo más sintetizar lo que quería mostrar que armar el código. El formato long lo cambie con pivot_wider.
Si bien el gráfico lo hice crudo, sin personalizar nada en la línea de código podemos ver que hay un filtro por player filter(player_name==input$nombresset) y por otro lado, si van a utilizar gráficos de ésta librería hay que usar la función renderHighchart.
Por otro lado, el resto de los indicadores de esa slide los hice con renderInfoBox tambien utilizando el filtro por player filter(player_name == input$nombresset)
#FACAS
output$facas <- renderInfoBox({
a <- df %>%
filter(player_name == input$nombresset)
a <- a %>% filter(name=='total_kills_knife')
a<- sum(a$value)
infoBox(
"Kills con Faca", a, icon = icon("list"),
color = "purple", fill = TRUE
)
})
Para el otro tabItem use:
Tiempo jugado
Ganados/Jugados
Kills/Shots
Headshot/Kills
Kills/Rounds
MVP/Matches
Deads por match
Puntos contribuidos por match
UI SIDE
fluidRow(
box(
title = "Deads por match", status = "primary", solidHeader = TRUE,
collapsible = TRUE, width = 6,
highchartOutput("plot8")
),
La FOSS4G es el evento de software open source y software libre geoespacial más grande del mundo. Es un encuentro organizado por la fundación OSGEO (Open Source Geospatial Foundation) y las comunidades locales de cada parte del planeta en la que participan desde programadores, investigadores, estudiantes, organismos no gubernamentales, empresas, docentes, etc. Dentro de la conferencia hay talleres, charlas, mapatones, stands y lo más importante el encuentro con personas.
Ésta vez fue la primera vez que participé y si bien no tenía mucha expectativa dado el formato virtual el nivel de la conferencia es INCREIBLE en cuanto a la calidad de las ponencias, talleres y también de la organización (desde la plataforma hasta la comunicación). En este sentido, hay que remarcar el trabajo que hicieron los Geoinquietos Argentina y la Asociación GeoLibres para poder llevar a cabo menuda conferencia poniendole el cuerpo a situaciones realmente dificiles y dolorosas.
De las cosas que más rescato de mi experiencia en la FOSS es la posibilidad de escuchar en primera persona las experiencias y trabajos de gente que uno admira. En mi caso, participe de un taller de Vector Tiles llevado a cabo por Map Tiler. Además de escuchar a los “viejos conocidos” el encuentro da la posibilidad de escuchar otras voces que son parte de la comunidad pero no son tan conocidas o activas en las redes y llevan a cabo un trabajo espectacular.
Otra de las cosas que más me gusto del encuentro – y pese a que el formato fue virtual – fue la posibilidad de poder hablar con gente. La plataforma tenía una interfaz en donde cada participante podía ser un personaje y a través de diferentes representaciones de la Ciudad uno se podía cruzar con gente y generar una video llamada. Ésto hizo que uno pueda seguir intercambiando data o conociendo gente más allá de las charlas o talleres.
Mi primer FOSS
Cómo suele pasar en la mayoría de los eventos en los que participo, primero me anoto y a partir de eso me obligo a presentar algún trabajo. En esta ocasión la charla que dí se basó en un indicador que construimos para el Ministerio de Cultura sobre accesibilidad física a espacios y actividades culturales en la Ciudad de Buenos Aires.
El trabajo se basa en calcular para cada una de las esquinas de la Ciudad la distancia peatonal a una serie de espacios culturales (Cines, Teatros, Clubes de Música, Bibliotecas, Museos, Espacios de Formación). Ésto implico, por un lado utilizar alguna herramienta de ruteo – en este caso fue OSRM – y poder programar un script que lupee las esquinas y además que disminuya el tiempo de procesamiento lo máximo posible.
Más allá del contexto del trabajo, éste fue una buena oportunidad para poner en práctica algunas cosas que vengo haciendo en R. Empece a estudiar éste lenguaje en diciembre 2019 y en estos dos años me obligue a usarlo literalmente casi todos los días ya sea para manejo de tablas, escrapeo, data wrangling, geoprocesos, desarrollo de dashboards etc.
Otro dato no menor es que la charla la hice 100% en ingles. Si bien estaba la posibilidad de hablar en castellano, la mayoría del público hablaba ingles (y las relaciones sur-sur no se van hacer solas) y eso también implicó un lindo desafio.
Para terminar el posteo, ojala que la FOSS4G2021 sea la primera de muchas otras (la próxima se hace en Florencia, Italia) . Y a modo personal, queda pendiente empezar a ver algunos videos de lo que fueron las presentaciones. Realmente hay material de estudio muy interesante para indagar.








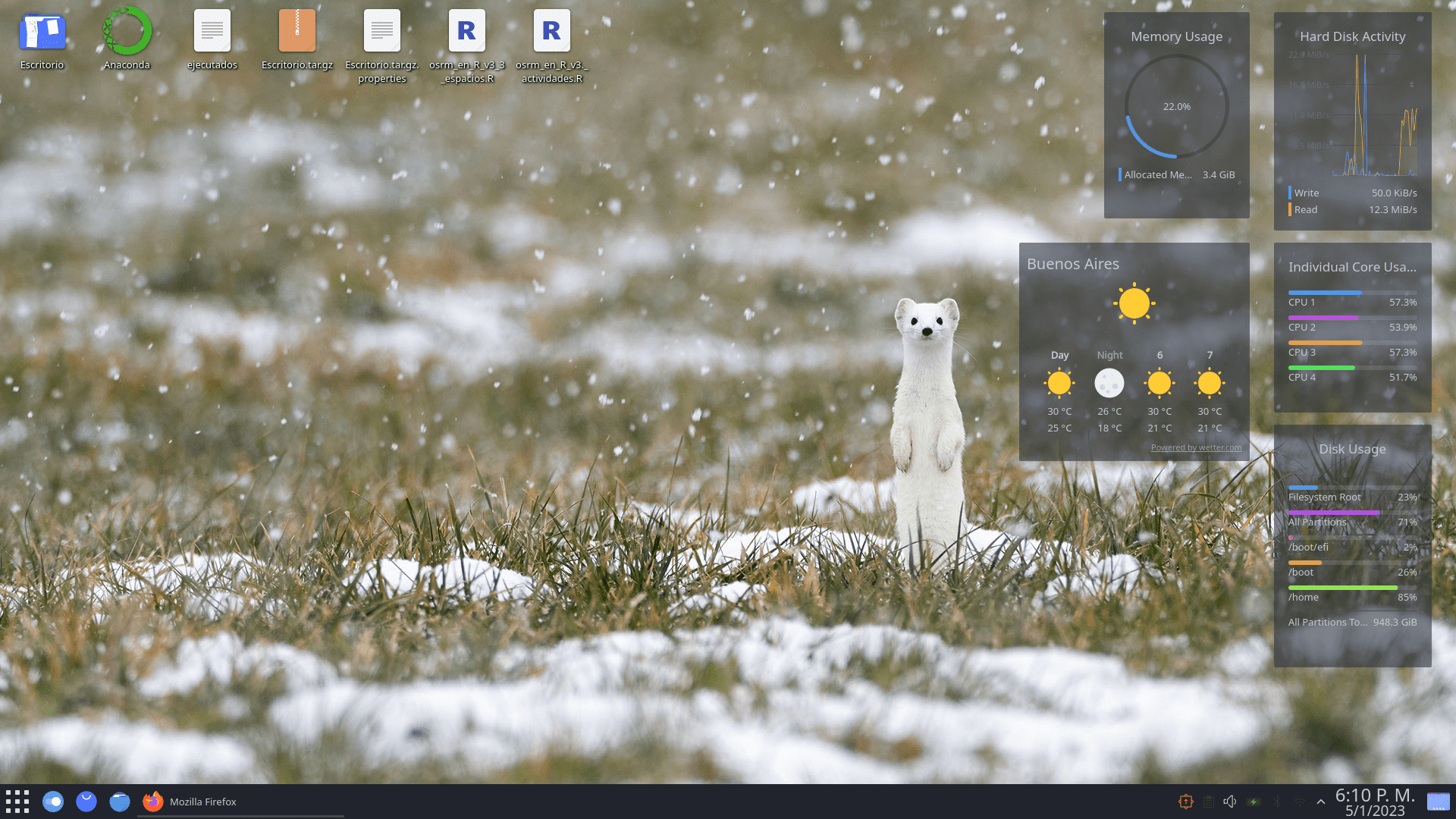 A la derecha de la pantalla, agregue unos widgets de rendimiento (memoria, cores, cpu use), una barra inferior con algunos íconos favoritos, que está abierto y el minimizador, y por último, arriba a la derecha otra barra con la hora y algunas opciones de dispositivos (wifi, bluetooth, conexión, display, avisos, sonido).
A la derecha de la pantalla, agregue unos widgets de rendimiento (memoria, cores, cpu use), una barra inferior con algunos íconos favoritos, que está abierto y el minimizador, y por último, arriba a la derecha otra barra con la hora y algunas opciones de dispositivos (wifi, bluetooth, conexión, display, avisos, sonido).






 Otra de las cosas que más me gusto del encuentro – y pese a que el formato fue virtual – fue la posibilidad de poder hablar con gente. La plataforma tenía una interfaz en donde cada participante podía ser un personaje y a través de diferentes representaciones de la Ciudad uno se podía cruzar con gente y generar una video llamada. Ésto hizo que uno pueda seguir intercambiando data o conociendo gente más allá de las charlas o talleres.
Otra de las cosas que más me gusto del encuentro – y pese a que el formato fue virtual – fue la posibilidad de poder hablar con gente. La plataforma tenía una interfaz en donde cada participante podía ser un personaje y a través de diferentes representaciones de la Ciudad uno se podía cruzar con gente y generar una video llamada. Ésto hizo que uno pueda seguir intercambiando data o conociendo gente más allá de las charlas o talleres.