La intención de está entrada es contar las primeras sensaciones usando Debian 11. En primer lugar, no soy administrador de sistemas ni un usuario avanzado de GNU Linux. Si bien desde el 2019 utilizo GNU Linux, en este tiempo no me dedique a estudiar el sistema en detalle. Solamente hacer instalaciones personales ( a través de Calamares), agregar o sacar repositorios e instalar y desinstalar programas con la terminal. Dado estos conocimientos básicos, Debian siempre había parecido un cuco. Tiene fama de ser dificil de usar y que es facil de “cagarla” sino estás muy en tema.
Mi historial GNU Linux
Cómo mencionaba, desde el 2019 elijo usar (cada vez que puedo) software libre. Si bien había tenido algunas experiencias anteriores, allá por el 2009 o 2010, instalando Ubuntu y Linux Mint en la búsqueda de una interfaz más similar a Windows, en ese entonces no sabía de la filosofía del Software Libre. Las experiencias habían sido buenas pero la necesidad de usar Arcmap me ancló a Windows.
En el 2019, me uní al Club del Software Libre y realicé un taller de instalación. El resultado fue tener un dual boot durante dos meses entre Windows 10 y Ubuntu Studio, y luego de eso me di cuenta que el Windows ya no lo usaba ni tampoco lo necesitaba.
Había elegido Ubuntu Studio porque me llamaba mucho la atención la cantidad de programas que venían enfocados a la producción audiovisual. Luego de unos meses cambie a Ubuntu Mate ya que los programas esos no los usaba y quería algo más limpio.
En estos años, Ubuntu (el 18 y el 21.04) anduvo muy bien. El sabor tenía todo lo que necesitaba, y los programas que uso (QGIS, R Studio, Anaconda, Inkscape, GIMP, Atom y Steam) también respondieron bien. Solo que estas últimas semanas empezó a fallar con algunos congelamientos que me forzaron a resetear y perder algunas cosas mínimas. Dado que estaba por tener vacaciones era el momento de probar una distro nueva, cosa que si tenía algún problema tenga el tiempo para arreglarlo o en el peor de los casos volver a una instalación limpia de Ubuntu.
Migrando a Debian
La principal fama de Debian es que es estable y eso es lo que estaba buscando después de tener esos congelamientos en la compu, un sistema estable que no se cuelgue. La segunda fama que tiene es que no es la más amigable para usuarios novatos. Con el primer punto – hasta ahora coincido – con el segundo no del todo.
Considero que es super importante probar la distribución antes de instalarla (a menos que tengamos una máquina de pruebas). En mi caso, armé una máquina virtual, por un lado, viendo el live, y por otro, para probar el instalador, a ver si tenía algo complicado o algo que tuviera que investigar.
Otro elemento relevante, es realizar la migración con tiempo. Cuando hablo de la migración, hablo desde el momento en que investigamos que distro queremos, probarla, instalarla e instalar los programas que usamos. Es decir, un tiempo pre instalación, y también un tiempo post instalación para dejar todo “pipicucu”.
A su vez, y no menos importante, pensar bien las particiones. Lo más facil es hacer la instalación automática, que el instalador se encargue de las particiones. El tema es que a largo plazo esto implica mayor tiempo de backup y más vueltas si queremos instalar varias distros, o si queremos volver a instalar una distro de cero. En mi caso, tengo una partición para el boot, otra swap, otra root y otra para el home (donde pongo mis archivos, documentos, descargas, bla). Esto me permitió que al tener el home en una partición aparte, todos mis archivos sigan estando con el mismo orden y en el mismo lugar, con la migración de Ubuntu a Debian.
El instalador que use se llama “Calamares” y basicamente es un instalador gráfico que te va diciendo que hacer (elegir donde estás, idioma, teclado, si queres particionar y la instalación). No recuerdo cuanto tiempo me llevo instalar pero habrá sido entre 15 y 30 minutos. La iso la descargue de este link que es la versión con controladores privativos. Y el sabor que elegi es KDE. Entiendo que puede haber otros instaladores en donde el usuario tiene mayor control de lo que instala, en mi caso no quise probar algo nuevo y la verdad que no hubo problema. Se instaló todo, resetie y CHAN… Error de Grub!
En ese momento putie un poco pero fue una falsa alarma. No se bien que hice, si desactive el secure boot, o pase a modo UEFI o que (esas son cosas que no entiendo mucho) pero al cambiar eso booteo perfecto y ya estaba usando Debian.
Los chiches de KDE
Una de las razones por las que elegí el sabor KDE sobre Mate (que venía usando antes) es que KDE tiene miles de opciones, widgets y cosas que hacen que la compu se vea re contra cheta. Creo que lo primero que hice con el sistema fue probar estas cosas y si bien hay templates de usuarios y se puede agregar botoncitos y “cositas” lo más funcional para mi sigue siendo lo más sobrio en cuanto a diseño.
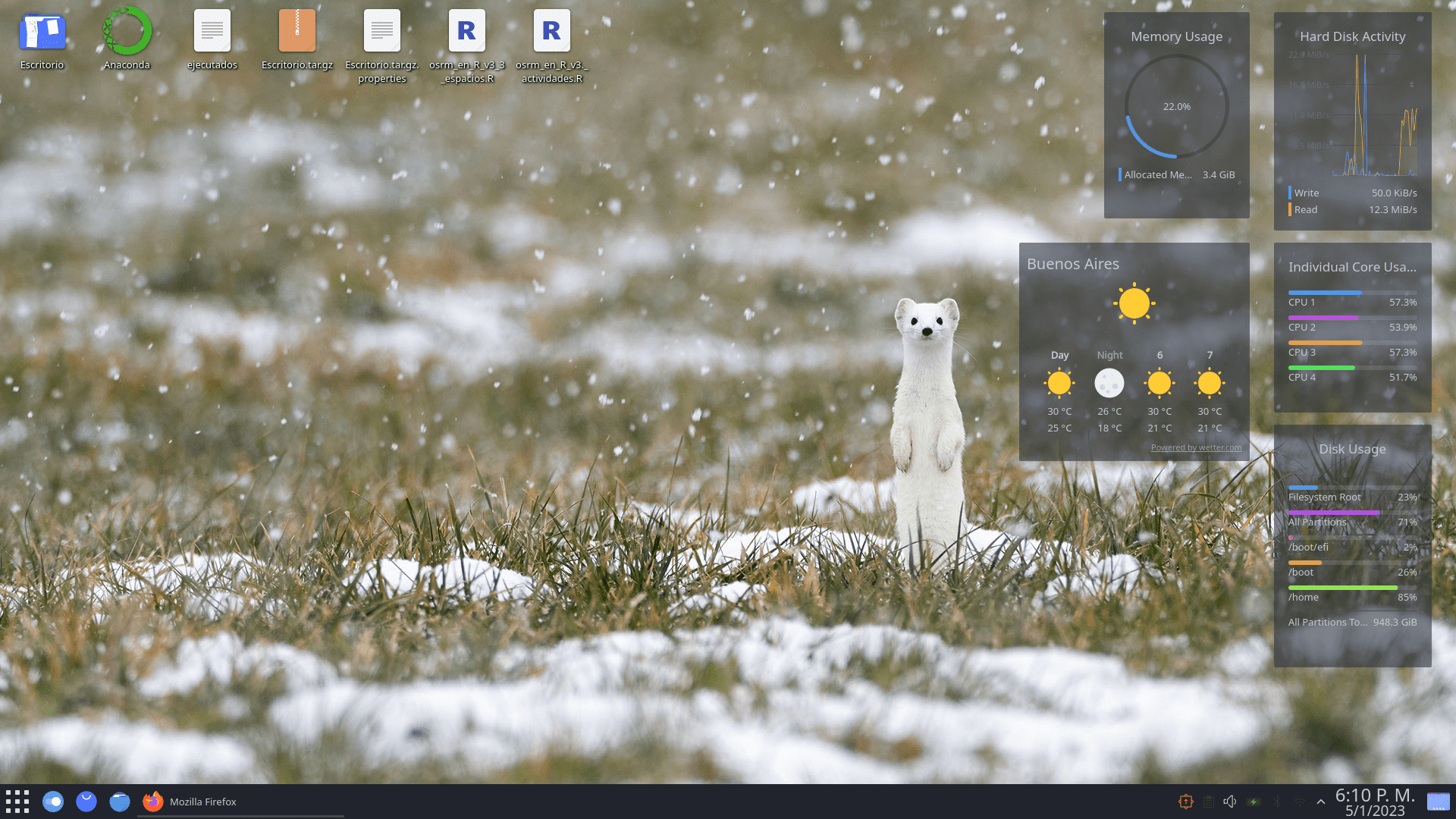 A la derecha de la pantalla, agregue unos widgets de rendimiento (memoria, cores, cpu use), una barra inferior con algunos íconos favoritos, que está abierto y el minimizador, y por último, arriba a la derecha otra barra con la hora y algunas opciones de dispositivos (wifi, bluetooth, conexión, display, avisos, sonido).
A la derecha de la pantalla, agregue unos widgets de rendimiento (memoria, cores, cpu use), una barra inferior con algunos íconos favoritos, que está abierto y el minimizador, y por último, arriba a la derecha otra barra con la hora y algunas opciones de dispositivos (wifi, bluetooth, conexión, display, avisos, sonido).
Instalación de aplicaciones
La instalación de aplicaciones, al menos las que uso yo, no difiere mucho de Ubuntu. Algunas están en el centro de software y otras se hacen a través de la sources.list. Por ejemplo, QGIS se puede instalar agregando repositorios o a través de Discover, el centro de software.
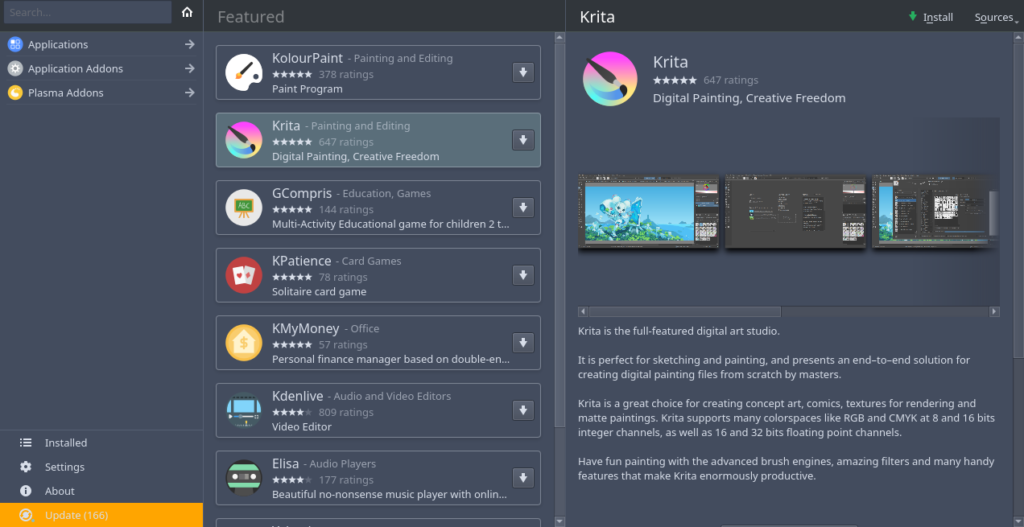
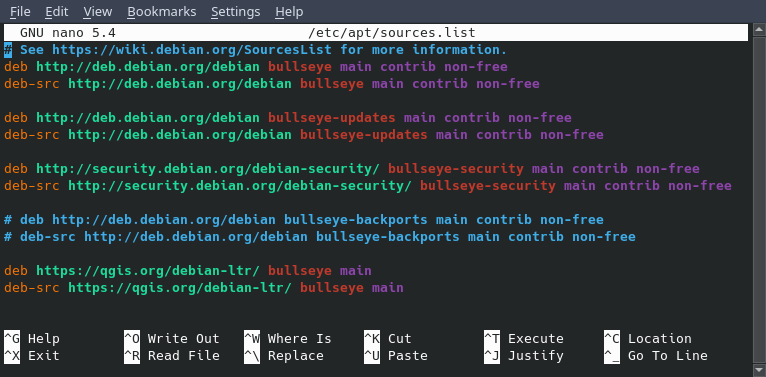
En cuanto a la sources.list simplemente tengo agregado repositorios non free y los repositorios de QGIS
Y los drivers?
La verdad es que la instalación que use me dejo todo andando: wifi, bluetooth, audio, mic, placa de video. Pero con esto último si hubo algunas idas y vueltas. Mi laptop tiene dos placas de video: una onboard y otra nVidia que uso para juegos. La instalación que hice yo instala drivers para la placa nVidia no privativos. Más allá de los drivers, privativos o no privativos, a la hora de correr juegos en Steam (el CSGO) lo primero que pasaba es que estos se ejecutaban usando la placa onboard, lo cual bajaban mucho los FPS.
Al instalar, los drivers privativos esto seguía sucediendo y ahi empecé a “meter mano”. Y si bien esta es una forma de aprender a veces podemos romper algunas cosas. En mi caso, el “meter mano” implico agregar repositorios de testing, backports, actualizar todo el sistema, y a partir de eso, actualicé kernel, drivers y demás. El resultado fue que los juegos empezaron a usar la placa de video nVidia pero después de unos minutos se tildaba todo al momento de jugar. Fuera de los juegos todo andaba impecable.
A partir de eso, decidí volver a atras instalando todo de 0. Cómo la instalación había sido fácil lo mejor era empezar con una instalación “fresca”. Si bien fueron varias horas con prueba, la placa funcionó. A diferencia de Ubuntu en donde había una opción de actualización en donde elegía que drivers quería, acá tuve que seguir algunos pasos que están muy bien documentados y a su vez, cuando quiero utilizar la placa tengo que ejecutar una serie de comandos para activarla. Algo asi como ejecutame esto usando tal placa. Seguramente esto se puede mejorar armando un acceso directo, por ahora esta solución me alcanza.

Todo el tema de los drivers nVidia fue lo que más dolor de cabeza me dio, creo que fue una buena experiencia para aprender un poco más del sistema. Por otro lado, quizás con los drivers no privativos probablemente también sirva esta solución, pero ahora prefiero no cambiar. Estoy con el kernel 5.10 y drivers nvidia 460…
Conclusiones prematuras
La experiencia usando Debian 11 viene siendo muy buena. Es cómo tener una compu nueva ( por rendimiento y por estética). La usabilidad del sistema para un usuario novato o seminovato cómo yo, hasta ahora es muy similar a Ubuntu. La instalación fue impecable y termino con todo operativo (uno de los miedos alrededor de GNU Linux). El tema de drivers nVidia puede ser algo hincha huevos pero puede pasar en todas las distribuciones pero a diferencia de Ubuntu (que es de donde vengo) creo que Debian tiene una documentación más robusta y no es poca cosa. En general, cualquier duda de Ubuntu la resolvía en stackexchange. En este caso, los primeros y mejores resultados fueron los que vienen de la wiki de Debian con paso a paso y explicaciones entendibles para usuarios no avanzados. Un ejemplo de esto, es que no solo muestran diferentes formas de instalar drivers privativos sino que hay una wiki especifica para usar Steam. En este sentido, y una de las cosas que más me sorprende del software libre vs el software privativo es la documentación y la ayuda de la comunidad. Para este último, hay un cierto “status quo” de la documentación y de las ayudas. En otras palabras, suele pasar que en los foros, las respuestas oficiales tienden “esto tiene que funcionar asi y punto!” (mirar foros de PowerBI o ESRI). Con el software libre, la documentación y las ayudas están más humanizadas entendiendo el ecosistema de usos y problemas que puede haber. Pero sin extenderme mucho en esto, me sorprendio y para bien la documentación en Debian.
Cómo conclusión final, la cantidad de distribuciones para probar es muy amplia y hay mucha variedad según que uso le demos a nuestras PC. En tanto y en cuanto, tengamos una máquina virtual para hacer pruebas y un poco de tiempo, mi recomendación es que investiguen y vean que es lo que buscan en su informática y seguramente encuentren una distribución GNU Linux que les cierre. Se van a dar cuenta que el software libre no solamente no muerde sino que es funcional y transparente.





 Otra de las cosas que más me gusto del encuentro – y pese a que el formato fue virtual – fue la posibilidad de poder hablar con gente. La plataforma tenía una interfaz en donde cada participante podía ser un personaje y a través de diferentes representaciones de la Ciudad uno se podía cruzar con gente y generar una video llamada. Ésto hizo que uno pueda seguir intercambiando data o conociendo gente más allá de las charlas o talleres.
Otra de las cosas que más me gusto del encuentro – y pese a que el formato fue virtual – fue la posibilidad de poder hablar con gente. La plataforma tenía una interfaz en donde cada participante podía ser un personaje y a través de diferentes representaciones de la Ciudad uno se podía cruzar con gente y generar una video llamada. Ésto hizo que uno pueda seguir intercambiando data o conociendo gente más allá de las charlas o talleres.